This post is based on lectures I have given on marketing analytics, with a particular focus on Google Analytics. When I teach, I like to start by covering some of the mechanics of web tracking because I think it helps bring clarity and meaning to the data we analyze.
What Happens When You Open a Web Page in a Browser?
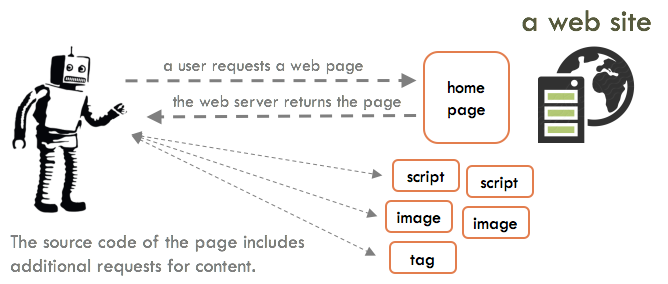
When you visit a web page in a browser, your browser sends a request for the page to a web server. The request includes the full URL of the page you are requesting and various other bits of information. The web server then sends a response, which typically includes the HTML source code of the web page you requested. The source code of the webpage includes HTML tags containing additional requests for resources that need to be retrieved in order to render the web page. These resources can include images, video files, JavaScript files, style sheets (CSS files), HTML files, and tracking tags. The additional resources do not always come from the same web server as the web page you requested.
Put another way, the web “page” you see in your browser is not a page at all, it is a collection of files that combine to create what you see in front of you.
| Try it yourself! 1. In Google Chrome, right click on a web page and select ‘Inspect’. 2. This will open Chrome Dev Tools to the Elements tab – in the top bar, click ‘Sources’. 3. The left pane in the Sources tab shows all of the files required to render the page you clicked – click on a file to see its contents. It is mind boggling (and a bit overwhelming) to see how much goes into a single page. |
Tracking Tags
If the website uses Google Analytics or some other form of web tracking, tracking tags are one of the things included in the source code of the page, and they create a record of your visit. As you browse the site, tracking tags continue to fire, sending additional bits of information to Google Analytics with each tracked interaction. This information includes but is not limited to:
-
- A user identifier
- The Google Analytics ID of the site
- Your IP address
- Your browser type and version (which also indicates whether you are on a mobile device)
- The page you requested
- The previous page you visited, if you clicked on a link to get to the page.
Every HTTP request also includes a variety of other fields, detailed here: https://en.wikipedia.org/wiki/List_of_HTTP_header_fields .
The tracking tag itself is typically JavaScript, though some tags will include a plain HTML version in case a user does not have JavaScript enabled. The information described above gets sent to the tracking server, where all that data is stored. The tag itself often looks innocuous, but it likely includes a file reference that returns a lot of additional JavaScript to your browser.
Most tracking systems use a cookie to keep track of who you are between page views and visits. However, cookies have never been a great way to identify users and privacy laws, and browser restrictions are making cookies less useful and reliable over time.
Cookies
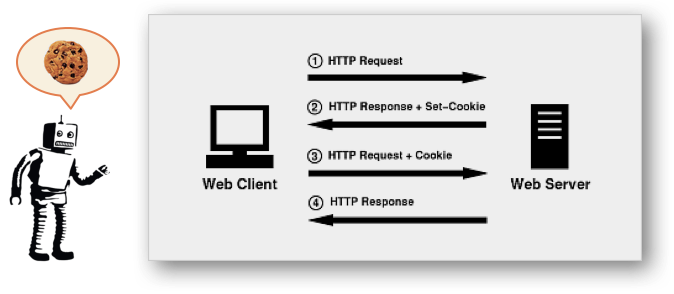
A cookie is a small text file stored in your browser cache by a web server (mostly analogous to a website). When you make a request of the same web server, the cookie is included with the request. There is a common misconception that cookies can expose your private information to malicious websites. This is not true. The information in a cookie is only available to the site that set the cookie. In other words, if you visit xyz.com, xyz.com only gets to see cookies set by xyz.com.
Tracking tags often set their own cookies. So, for example, if you visit xyz.com, you might get an xyz.com cookie and a facebook.com cookie that gets set by a Facebook tracking tag. The Google Analytics tag also sets cookies, but it sets them to the website’s own domain.
| Try it yourself! 1. In Google Chrome, click the lock icon on the left side of the navigation bar 2. Then click ‘Cookies’ 3. From there you can see which domains have set cookies on the page. You can click on a domain to expand it and see the cookies that have been set. You can even see exactly what is in each cookie! |
Most of the time, a cookie is used to associate a visitor with a user account or a set of preferences. For example, if you visit amazon.com, Amazon identifies you with a cookie and presents personalized content. In this case, the cookie stores a unique identifier, but no personal information. Web developers do sometimes store personal information in cookies, but this is considered bad practice and pretty rare. Major players such as Google and Facebook never store personal information in cookies.
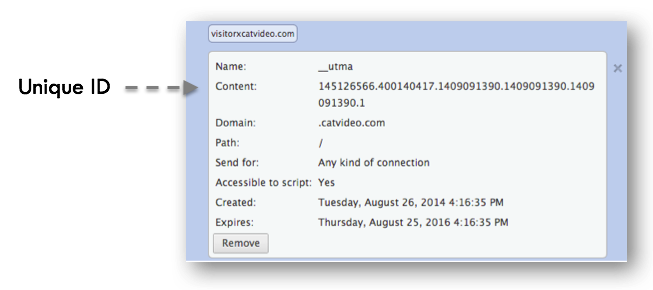
Below is an example of the contents of an actual cookie.
Third-party vs. first-party cookies
A cookie is referred to as “third-party” when it is set by a domain that is different from the website you are visiting. For example, if you install a Facebook tracking tag on a website it sets a facebook.com cookie. This has allowed Facebook and most other online advertising platforms to track users as they browse the web and target them with personalized advertising. In response to user demand and privacy regulations, all major browsers have made it easy for users to block third-party cookies. The most popular browser, Google Chrome, will be defaulting to blocking cookies by the end of 2024. In general, the digital marketing world is planning for a post-third-party-cookie world.
A cookie is referred to as “first-party” if it is set by the site you are visiting. Per above, first-party cookies are the main way websites keep track of who you are, which is necessary to support features like recommendations, shopping carts, user preferences and a variety of other features that are critical to most of the websites we visit. As such, first-party cookies are likely going to be around for a while. But while it continues to be technically feasible to store user identifiers in cookies, privacy regulations are having an impact on if and how individual users get tracked by websites. One of the behind-the-scenes advances of GA4 is that it can report on aggregate behavior without storing data that is tied to specific users. This has little-to-no impact on what you see as a user of GA4, and means you can accommodate users’ preferences and comply with privacy regulations while you continue to collect and analyze behavioral data.
Domains, Sub-domains
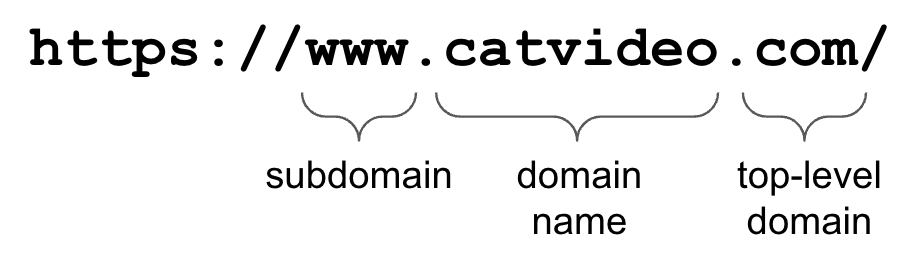
The domain is the part of the URL that comes before a slash or question mark. It acts as a pointer to a domain name server, which maps the domain name to an IP address. The dots in a domain are really important – they separate the levels of the domain and get more specific as you go from right to left.
shop.catvideo.com and www.catvideo.com, for example, are two different domains. “shop” and “www” in this case are referred to as sub-domains, or third-level domains, because they are the third part of the domain name. The second-level domain is usually just called the domain name, though people often refer to the whole domain as the domain name as well.
If a cookie is set to xyz.com, both www.xyz.com and store.xyz.com will receive the cookie when the user makes a request, since both are part of xyz.com. This matters for GA tracking, because GA will set a user-identifier cookie on the second-level domain by default[1]. As long as the user stays within xyz.com, he/she is tracked as a single user. If he/she jumps to another domain, xyz.shopify.com, for example, GA will create a new user session unless configuration changes are made in the Google Analytics tag to link the two domains. These configuration changes are referred to as cross-domain tracking.
The top-level domain, or TLD, is the most general part of the domain. What TLDs represent and how they came to be is not particularly relevant to analytics, but if you are curious there’s a bit more info below.
|
What’s in a name? The top-level domain (TLD) designates the domain name registration authority for a domain. “.com” was one of the first TLDs and stands for “commercial”. It was intended to designate a business, but nowadays anyone can register a “.com” domain. Some TLDs are still pretty strictly controlled. “.gov”, for example, indicates a US governmental organization and “.mil” is US military. Nearly all countries have their own TLDs as well, which match their two-character country codes. “.ca” is the Canadian TLD, for example. Some countries created second-level domains for different types of organizations. “.co.uk” is one of these, and was originally created to designate UK commercial domains. While technically “.co” in this case is a second-level domain, “.co.uk” behaves like a TLD and you can think of it as such. The domain name system has expanded quite a lot in recent years, which is why we are starting to see longer and very-specific TLDs. If you can’t register the domain name you want as a “.com”, you might be able to as “.info”, “.online” or one of hundreds of other TLDs that have become available. The Internet Corporation for Assigned Names and Numbers (ICANN) administers the whole, complicated system. You can see the complete list of TLDs on their site. |
From a tracking standpoint, the main thing to know about domains is that cookies are set to a specific domain. They can be set to the second or third level.
If a cookie is set to xyz.com, both www.xyz.com and store.xyz.com will receive the cookie when the user makes a request, since both are part of xyz.com. This matters for GA tracking, because GA will set a user-identifier cookie on the second-level domain by default. As long as the user stays within xyz.com, he/she is tracked as a single user. If he/she jumps to another domain, xyz.shopify.com, for example, GA will create a new user session unless configuration changes are made in the Google Analytics tag to link the two domains. These configuration changes are referred to as cross-domain tracking.
IP Addresses
An IP (internet protocol) address is a group of numbers or numbers and letters that specify a location on the Internet. Anything that travels over the internet, such as a web page request or a sent email, gets routed to an IP address. A domain name is really just an alias for an IP address that serves two main functions:
-
- It is easier to remember and can be personalized to the owner. For example, our domain name, twooctobers.com, matches our business name.
- It provides a layer of abstraction from the actual IP address of a website or server. This means you can change the IP address a domain name points to without changing the domain name.
The translation of domain names to IP addresses happens via the Domain Name System (DNS), which you likely encountered if you have ever set up a website.
An example of an IP address: 73.243.52.93
Type “what is my IP address” in Google to see your IP address.
This example looks a lot different than the previous example. This is because there are two IP address systems currently in use. The second example uses the newer protocol, IPv6, which allows for a lot more addresses on the Internet.
Most of the time, an IP address can also be linked to a physical location, though often the location can only be known generally. That matters for web tracking because IP addresses are one of the main signals Google Analytics and other tracking tools use to infer the locations of website visitors.
If you are connecting to the Internet through a business, ISP or mobile carrier, your IP address is assigned dynamically from a group of addresses, and cannot be traced back to you personally. In other words, web sites can’t know who you are just from your IP address. They may, however, know where you work, and they definitely know what ISP or mobile carrier you use. Google Analytics uses IP address data to determine the networks users are coming from, but doesn’t go as far as inferring specific businesses visitors work at.
Paths and URL Parameters
In addition to a domain name, a URL can include a path and URL parameters.
The path is the portion of the URL that comes after the domain name, and is ostensibly the path to a document on a web server.

I say ‘ostensibly’ because in the early days a website actually was a collection of documents on a server. Nowadays, many websites dynamically serve content based on the full URL and the path isn’t actually a document path.
This distinction can matter for tracking because tracking tags generally load when a new request is sent to the web server and a “page” loads in the browser. This was straightforward when pages were actual documents, but can get tricky when URL changes do not result in new page loads. For this and other reasons, the powers that be on the web developed a standard for reporting “history changes” in a browser session that are not tied to an actual page load. GA4 automatically tracks history changes as page views, but Universal Analytics and many other tracking tools do not.
The URL parameters (AKA ‘query parameters’ or ‘querystring’) is the set of parameters that come after the question mark in the URL. It passes variables to a web page/application. It is formed as name/value pairs.
In the example below, there are two URL parameters: type, and disposition. This example might describe a scenario where a user has selected the filters “tabby” and “crazy” when viewing cat videos on the gallery page of catvideo.com. Don’t get too excited, this is just an example and not a real site.

The URL parameters are an important component of tracking, because most tracking systems have built-in support for specific parameters. Google Analytics, for example, supports several parameters that can be used to track the source of traffic, called UTM parameters. We’ll cover these in more detail later, but in summary you can add UTM parameters to a URL you use in a social post, ad or email that will associate specific source and campaign information with a visit.
URL parameters can also muddy up your analytics data because they may or may not be tied to unique content on a page. For example, some website platforms include a parameter that is specific to a user visiting a site. In the example below, a “user_id” parameter has been added to our catvideo.com example. The website might do this to keep track of which videos a given user has watched, or to personalize the experience in some other way.

This can make it difficult to analyze the performance of specific pages because a single page shows up as thousands of different pages in GA due to the user ID parameter. It is fairly common to find URL parameters that have functional value to the website, but are not of interest to analysts who are trying to understand which pages get viewed the most or other usage metrics.
You can tell GA to ignore certain parameters to prevent this from happening.
Tracking Interactions Other Than Page Views
So far we have talked about the mechanics of putting a tag on a web page that sends information about a user to a tracking server, including detailed information about the page a user is visiting. This is great for knowing what pages users are looking at, but what if we want to know other things about their behavior? Here are some of the things we might want to track:
-
- Video views
- On-site searches
- Scrolling
- Button or link clicks
- Form submits
- Shopping behavior: adds-to-cart, checkout and purchases
- Logins/logouts
- Sign ups
Each website is different, but odds are at least some of these (or other) interactions are of interest for any website you look at. Fortunately, we can track virtually any and all user interactions using JavaScript. Historically, tracking platforms have been very page-view-centric, but GA4 tracks the first four interactions listed above automatically and has a robust architecture for tracking a wide variety of pre-defined or custom events.
Here is an example of a tag that tracks user logins in GA4:
gtag("event", "login", {
method: "Google"
});
Simple, right?
A very brief overview of JavaScript
JavaScript is a robust programming language with a variety of applications, but we’ll keep our discussion limited to the aspects of JavaScript that are relevant to tracking.
JavaScript provides programmatic access to and control over pretty much anything that happens in a browser. For tracking purposes we aren’t generally interested in changing what a user sees, but we are very interested in seeing what a user does on a site. JavaScript has a built-in event model that we can use to listen for various events, including clicks, typing, mouse movements, form submits and scrolling. The event model doesn’t have a pre-determined, fixed set of events it supports, these are just some of the events that are commonly supported in browsers. Software developers are free to create any event they want. Think of it as a notification system – you are writing a piece of software that you want to do X over here when Y happens over there.
When we tell JavaScript that we want to do X when Y happens, that is called adding an event listener. We can attach event listeners to specific elements on a web page. For example, we can tell JavaScript to fire an analytics tag when a user clicks on a specific button.
| Try it yourself! 1. In Google Chrome, right click on a web page and select ‘Inspect’. 2. This will open Chrome Dev Tools to the Elements tab – in the top bar, click ‘Console’. This opens the JavaScript Console, which enables you to execute JavaScript on the page. 3. Copy/paste the following code to the JavaScript prompt and hit enter/return window.addEventListener(“click”, function(){ alert(“A click happened!”); }); 4. Now click anywhere on the web page you opened the console from. You should see an alert box pop up with your message! |
Note that executing JavaScript in the console like this only affects your experience of the page – you can’t make changes that other users will see.
JavaScript also gives us the ability to get text or other values from elements on a web page. For example, we can use JavaScript to get order IDs and purchase totals from a shopping cart order confirmation page (most of the time). We do this by accessing what is called the document object model (DOM) in JavaScript. The DOM is essentially the entire contents of a web page translated into JavaScript. Every word, image and markup tag is available to JavaScript via the DOM.
You may be wondering, “do I have to be a JavaScript programmer to track button clicks, video views and all that?” Fortunately, no. Google Tag Manager and other tag management tools make it easy to attach specific tags to specific events without writing any code. You will, however, have a much easier time understanding what’s going on in Tag Manager and how to troubleshoot issues if you have some familiarity with the DOM and rudimentary JavaScript.
|
Definition time!
|
Reporting on Tracking Data
Everything we have talked about so far pertains to how a web tracking system collects data. The other key parts of a tracking system are data aggregation and reporting. The fundamentals of how data gets collected are fairly similar between most analytics platforms, but how they aggregate data varies a fair amount, and how they report on data varies a lot. I’ll be going into reporting in a lot more detail later on, particularly with regards to Google Analytics, but aggregation happens under-the-hood, so I’ll describe it a bit here.
Why aggregate?
When you sum up all of the tracked interactions that happen on even a relatively small website, they can easily run into millions of records per month. For most reporting and analysis purposes it is not practical to report on this type of data, so tracking platforms aggregate data by various dimensions that are used in reporting. For example, behind the scenes a tracking system might summarize metrics such as page views and sessions by day, to make reporting faster and to economize on data storage space.
Data aggregation also allows a platform to report on metrics that would be prohibitive to calculate real-time. For example, reporting on the lifetime value of a visitor is manageable if data is aggregated by user in advance, but would require a lot of back-end processing if it had to be calculated on the fly every time a report was generated.
An implication of data aggregation is that some dimensions and metrics are not compatible with each other. For example, lifetime value is associated with a user, while average load time is associated with a page. You can’t report on the average load time of a user. In this example the two metrics are fundamentally incompatible, but there are other cases where data just gets lost as a result of aggregation. For example, detailed order information such as shipping fees might be available in ecommerce reporting, but might not be when reporting on dimensions such as landing page or gender. If you are putting together a report and run into a circumstance where you can’t add a particular dimension or metric, there is a good chance it is incompatible or unavailable with the dimensions or metrics you have already added.
Some reporting platforms also remove or restrict data for privacy reasons. For example, Google Analytics does collect IP address data, but it is not available anywhere in reporting because it is possible in some cases to identify an individual user by IP address. GA also limits or prevents demographics and interest reporting when a data sample is small. The reason for this is that an astute analyst could conceivably deduce who a person is by using a combination of location, age, gender and interests.
Key Takeaways
What has been described so far are the mechanics of how web analytics data is collected and sent to an analytics system such as GA. To recap, tracking tags send a series of messages about the characteristics and activity of each visitor on a website. The analytics system then aggregates the data into various data structures for reporting on a variety of dimensions and metrics. Dimensions define what we are reporting on, and metrics are aggregated values that describe characteristics of the group of people or things in our reports.
Tracking systems are great at tracking and reporting on interactions like page views, purchases and form submits, but not so great at reporting on the behavior of people over time. For example, because a visitor is usually identified by means of a cookie which is associated with a browser and a website, the visitor will likely appear as two people if they switch browsers or devices. This highlights a critical limitation of web analytics systems. According to the Internet Advertising Bureau, 78% of internet users browse with both mobile and desktop devices, and device usage is getting ever more fragmented with personal assistants, tablets & etc. Some analytics systems have capabilities to track people across devices, but none are very effective. This means you have a limited view of how individual visitors behave on your website over time, which is a significant drawback when it comes to analyzing behavioral data.
