Follow along as I identify & filter a GA4 bot
One down, infinity to go
A couple of months ago I noticed a traffic surge on a GA4 property I work with. The surge was pretty dramatic, so I did some investigating.
One of the first things I noticed was that the surge was entirely composed of Direct traffic, which was a big red flag. There is no legitimate circumstance in which Direct traffic grows significantly without at least some increase in Organic Search. This is because many users navigate to a website by way of Google search. When Direct traffic is disproportionately high, it is usually a symptom of a tracking implementation issue. When it surges without any growth in other channels, it is usually a symptom of bot traffic.
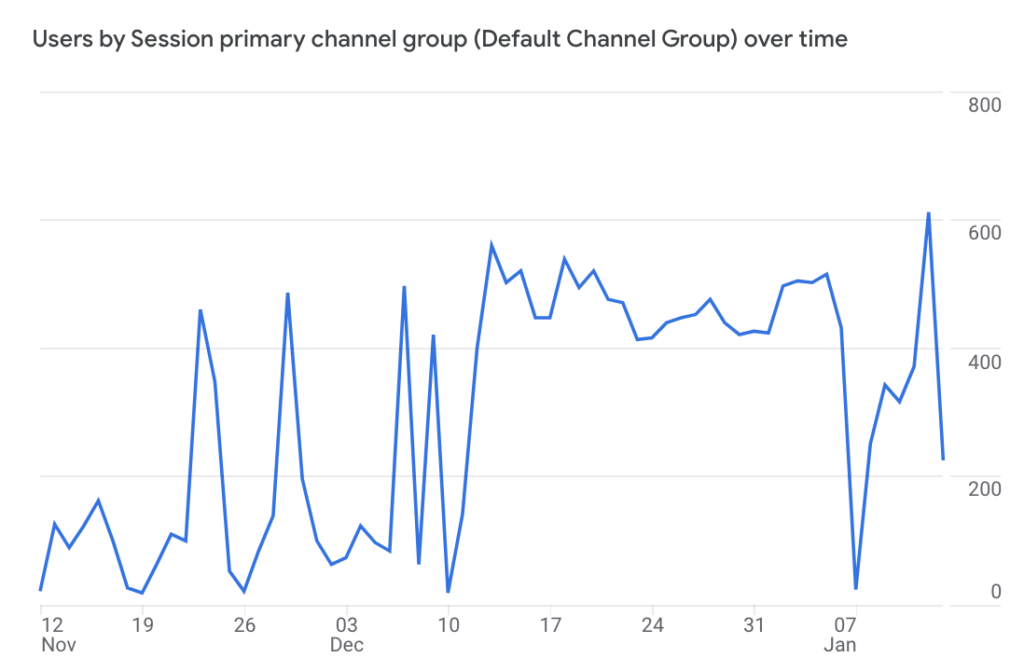
Daily sessions filtered to only include Direct traffic
So, I went hunting for bots.
Almost two months later, I am happy to say I found my bot and successfully excluded it from reporting. I made many missteps along the way and learned a lot. I hope sharing what I discovered, tested and learned will benefit you when you go on your own bot hunting expedition in GA4.
Understanding the nature of the bot
The first thing I did was to look for characteristics I might be able to use to identify and ultimately exclude the bot. (Check out my blog post How to identify bot traffic in GA4 for some ideas on how to do approach this diagnosis.) I tested different dimensions in GA4 reporting, and quickly isolated a few dimensions that correlated to extremely low engagement rates. Not all bots exhibit low engagement, but when you see an engagement rate that is in the low single digits, it probably doesn’t represent humans.
The characteristics I identified were:
- Browser = Chrome
- OS with version = Windows 10
- Country = (not set)
The first two aren’t very useful by themselves, since a large percentage of human visitors are on Windows 10 and Chrome, but the last one is very unusual. There are legitimate reasons why GA4 can fail to locate a visitor’s country of origin, but the percentage is usually well below 1% of traffic. For this site, it was almost 50%.
I used the combination of these dimensions to create a segment in a GA4 Exploration for further analysis. Explorations have two key benefits over regular reporting for this type of investigation:
- You can apply segments and they automatically save with the Exploration
- You can apply multiple dimensions to a tabular report at the same time
The segment was a bit tricky to create – it turns out that it doesn’t work to create a condition that Country = (not set) – apparently “(not set)” is just a placeholder in the UX for a null value. So I created a simple regular expression that includes events when the value for Country does not begin with a letter.
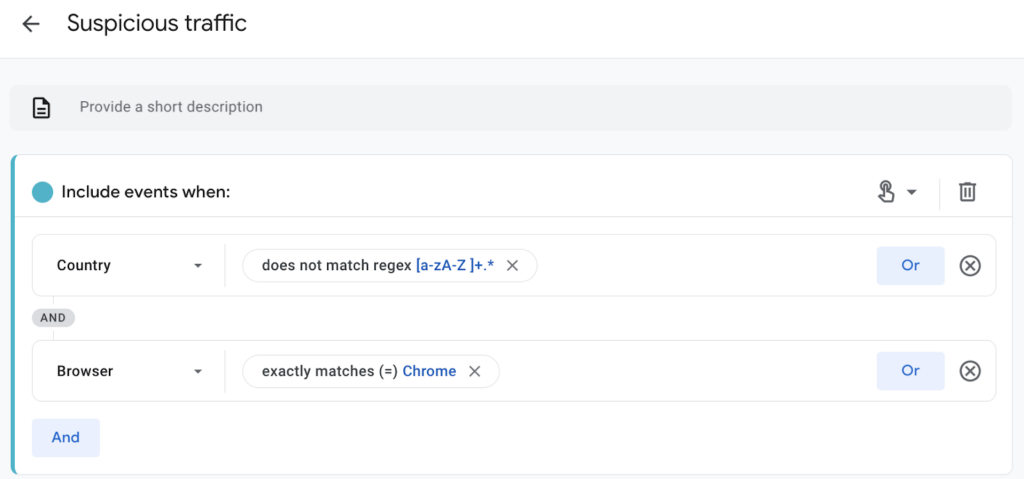
With my new ‘Suspicious traffic’ segment, I did a bit more investigation of dimensions that might correlate with the bot. I didn’t find anything better than Country = (not set), which appeared to include a small amount of legitimate traffic. Hoping to find something more definitive, I then moved on to phase 2: looking for IP addresses to exclude.
Before I describe my next step, let me describe the basics of traffic filtering in GA4, since it provides useful context for what I was trying to do….
A quick overview of filtering bots in GA4
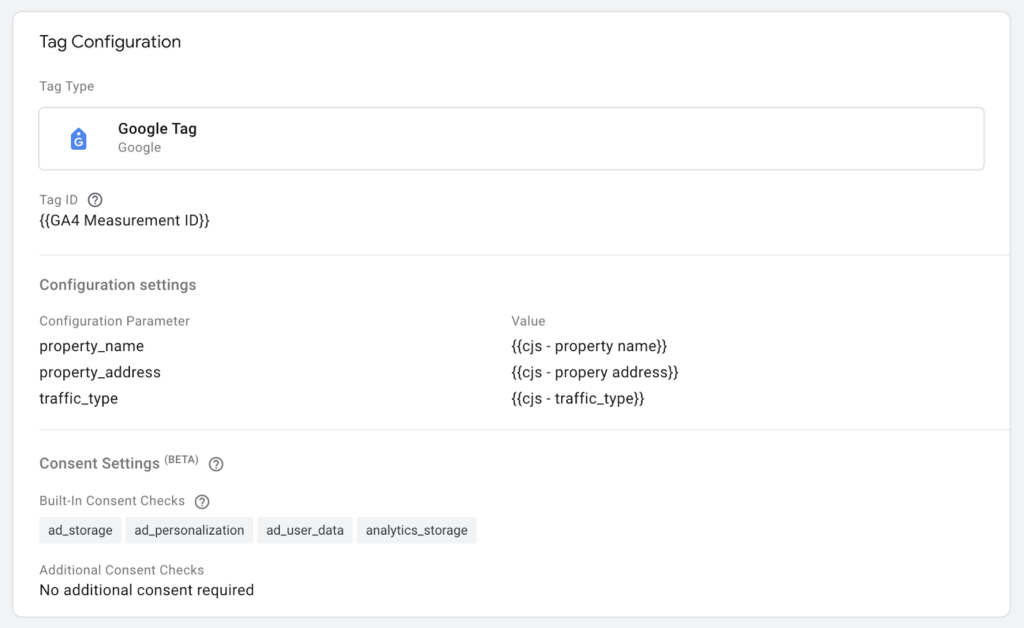
I like to use the Internal traffic filters setting in GA4 to set a Traffic filter without an internal traffic rule, which gives you a lot of power to exclude traffic using Google Tag Manager (GTM). I create a traffic_type variable with javascript in GTM and add a Traffic filter in GA4 based on the value set there. This process is described in more detail in my blog How to Filter Bot Traffic from GA4.
This is the technique I wanted to use to exclude the bot traffic from GA4 data. I just needed to figure out how to define the characteristics of this bot in a way we could detect with javascript. And so the investigation continued….
IP misadventures – part 1
An irony of GA4 is that the only built-in filtering capability is based on IP addresses, but GA4 does not store or report on IP addresses! So you need to use something other than GA4 to identify suspicious IP addresses.
At this point, I did attempt to get web server log files, which include IP addresses, but I hit a bit of a dead end. It would be difficult to relate log files to GA4 activity, but I was hoping the culprit would be glaringly obvious – if I found a small number of IP addresses making requests day in and day out, that would most likely be my bot. Lacking access to log files, I tried a workaround. A user’s IP address is not easy to get in Google Tag Manager, but it is possible with the help of an API. I added a Custom HTML tag in GTM to push a portion of the IP address to the JavaScript DataLayer:
IP misadventures – part 2
About a month went by, and I got an alert. I had a GA4 Insight set up to notify me of significant traffic drops, and upon investigation I discovered that the bot had taken a break for a day. That caused a precipitous traffic drop, which triggered the alert. My frustration with my previous failure had subsided, so I decided to reach back out to the developers to see if I could get some log files. This time, they got right back to me with what I needed.
I now had about 100,000 rows of web server log data to comb through. On my first run through, I just did a simple count of IP addresses in the log file. A couple of IP addresses stood out, so I did a reverse lookup, and GOTCHA!
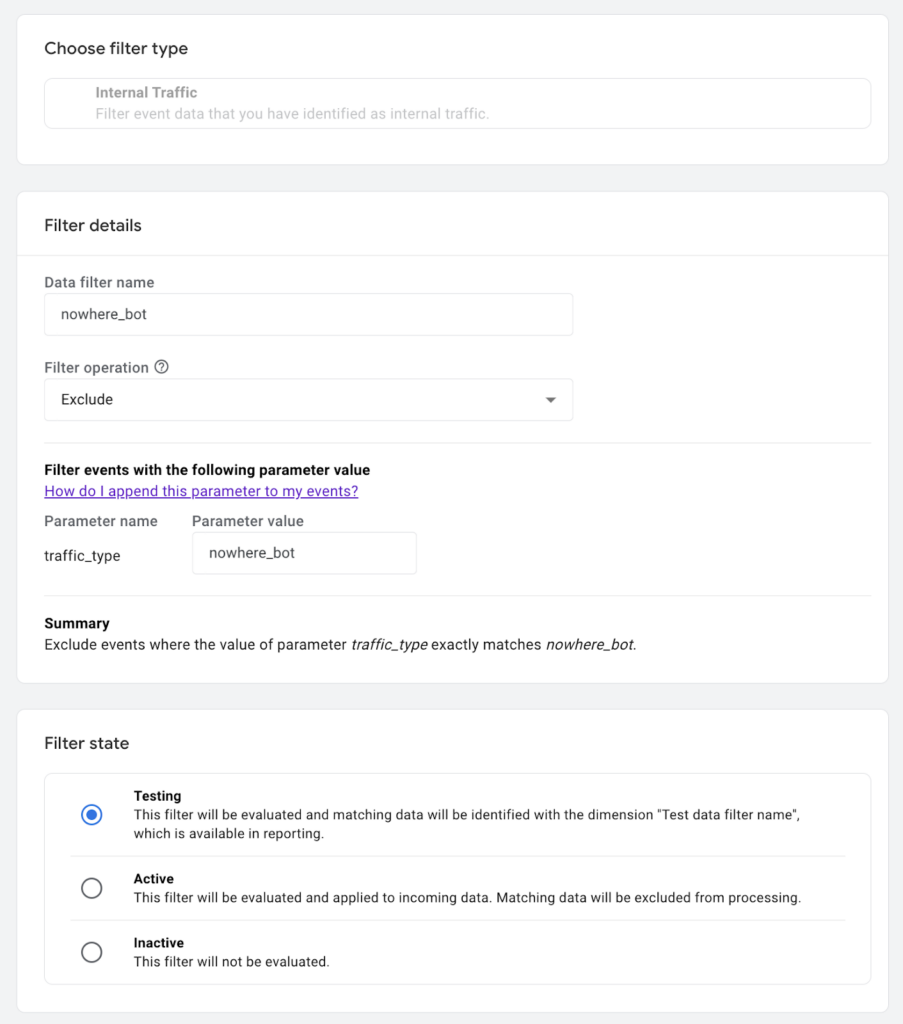
They were Amazon Web Services (AWS) addresses. Why would a human being be visiting from an AWS address? No good reason, but AWS would be a likely home for a bot. I created a filter based on the IPs and left it in testing mode so I could see if the AWS traffic correlated to the suspicious traffic segment I had created.
When I create IP filters, I usually do so with a /24 mask. This is what’s called CIDR notation, and it means I’m filtering 255 addresses in a range. For example, 172.65.8.0/24 filters the IP addresses 172.65.8.1 – 172.65.8.255. I do that because Internet-connected routers are typically assigned a pool of addresses versus a single address. They then allocate addresses dynamically from the pool to connected nodes. A common mistake people make is to filter a single address. That works until the router assigns a new address to the offending visitor. My approach runs the risk of filtering out legitimate traffic, but under most circumstances that risk is exceedingly small, and worth it for the benefit of excluding unwanted traffic.
I let my filter gather data for a few days, then looked at the results. There is a GA4 dimension, ‘Test data filter name’, that you can use to report on the value of the traffic_type parameter when it is associated with a filter set to ‘Testing’ mode. The dimension doesn’t exist in any standard report, but you can use it in Explorations. I created an Exploration to do so, but unfortunately no joy. Only a few visits were labeled ‘aws’ and they did not fall in my Suspicious traffic segment. I theorized that my IP filters were not incorrect, just incomplete, since a cloud service like AWS is likely to have a lot more than 255 addresses assigned to it.
So I then went looking for a list of AWS IP addresses, and found this list published by Amazon. The downloadable list of addresses is in JSON format, so I wrote a little parser to import them into a Google Sheet to make them a little easier to work with.
It turns out that AWS has hundreds of blocks of addresses. My whois lookup indicated that the addresses I was looking for were US-based, so that narrowed things down a lot, but the maximum number of addresses/blocks you can add to a GA4 IP filter is ten, so I had to be pretty choosy. I added the blocks that included the addresses I had spotted, plus some of the biggest blocks included in Amazon’s list.
Then I let data collect for a few more days, and still no joy. I went back to the log files and had an epiphany – web server log files include every request made of the server. That means every admin page, script file, image, etc. I cleaned the log file of everything but publicly accessible HTML page requests from Chrome browsers and Windows 10. I then analyzed what was left.
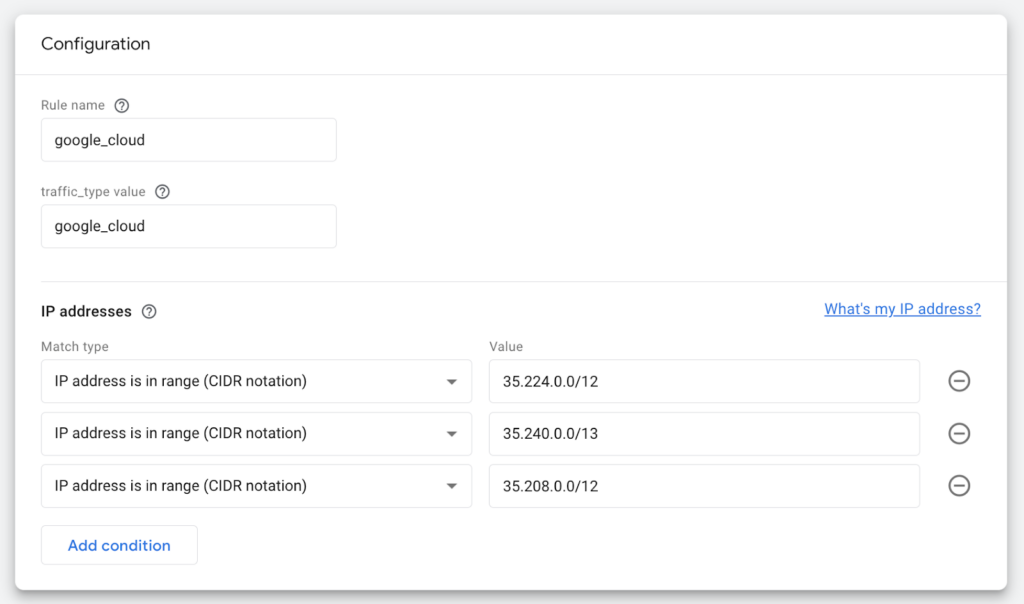
This time, I wrote a custom-formula script in Sheets to do reverse-IP lookups in bulk. A new pattern was revealed in the results: a significant percentage of the traffic came from Google Cloud. I found a repository of Google Cloud IP addresses – note that this resource includes a variety cloud computing providers, very handy! I then followed a similar process to what I had done with the Amazon addresses to create an IP filter. Like AWS, Google Cloud provisions hundreds of IP ranges, so my filter might be helpful for diagnosis, but I wouldn’t be able to rely on it to block all of the bot traffic.
This is what my Google Cloud IP filter ended up looking like:
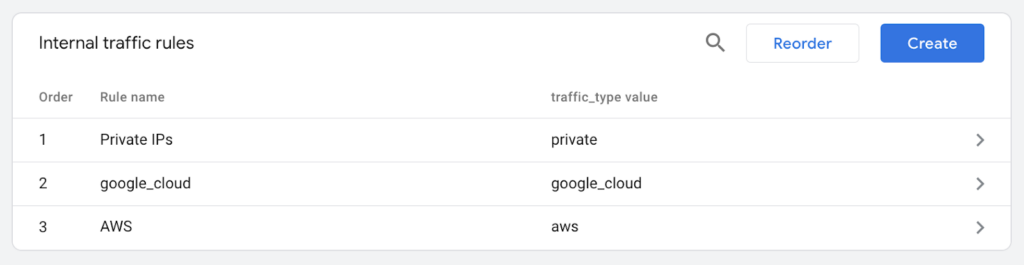
Here are the Internal traffic rules I ended up with. Ignore the Private IP rule – that hypothesis was so boneheaded I don’t even want to mention it.
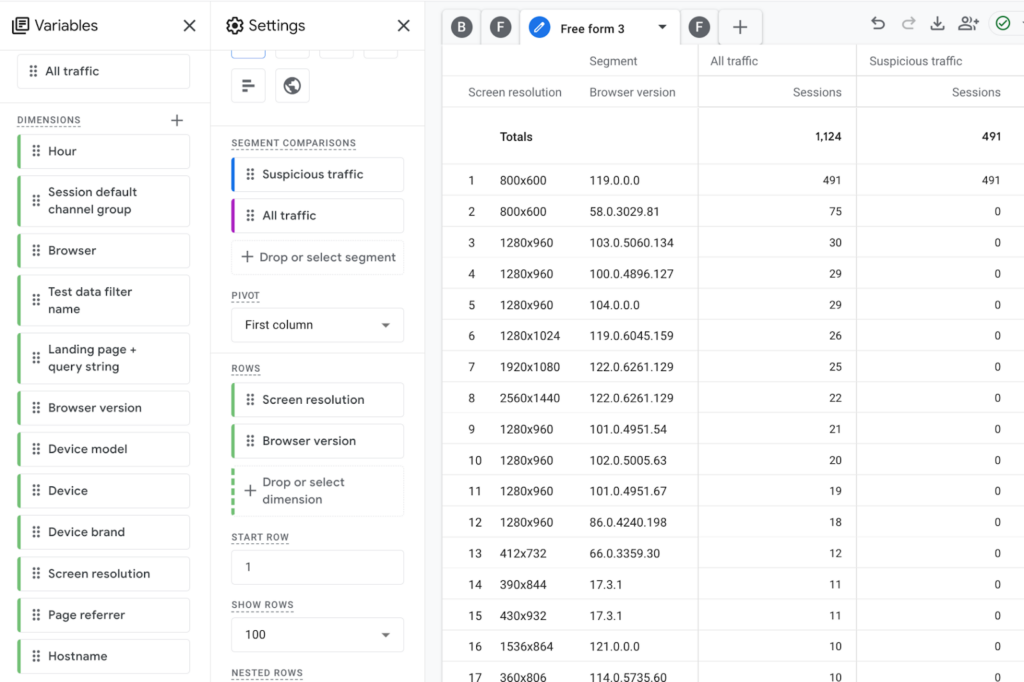
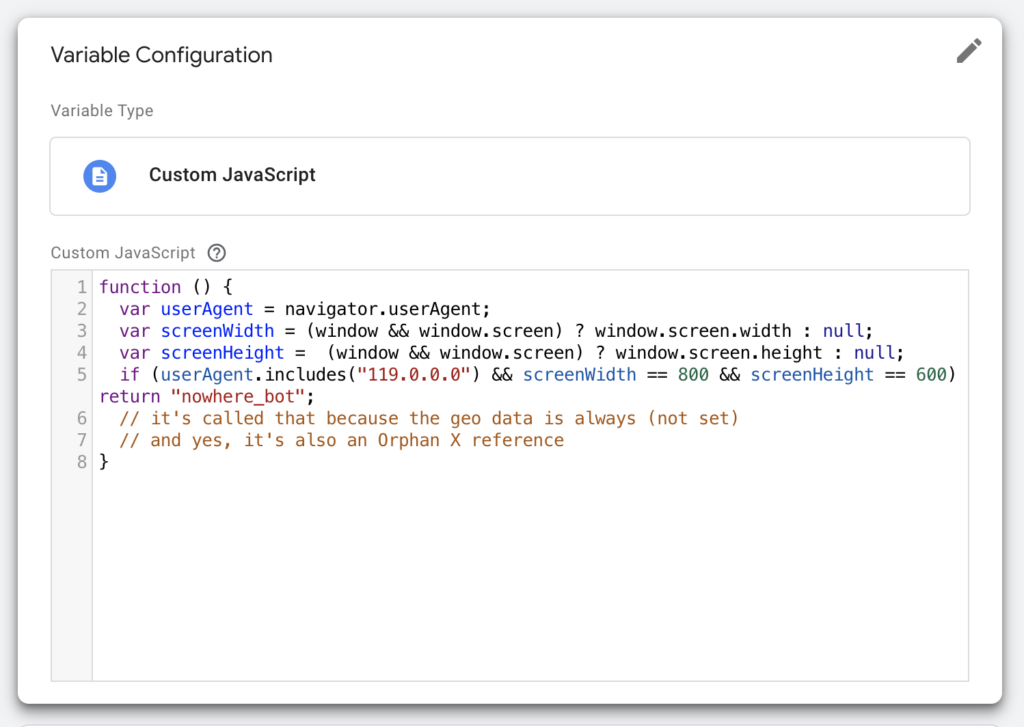
So I dug a little deeper into the log file. I quickly observed that all of the traffic coming from Google Cloud had the same browser version, Chrome 19.0.0.0. I looked at Chrome’s version history, and this version dates back to October 2023. I also noticed that the screen resolution associated with these requests was 800×600. That was a very common screen resolution in the 90’s, but exceedingly rare today, at least for humans.
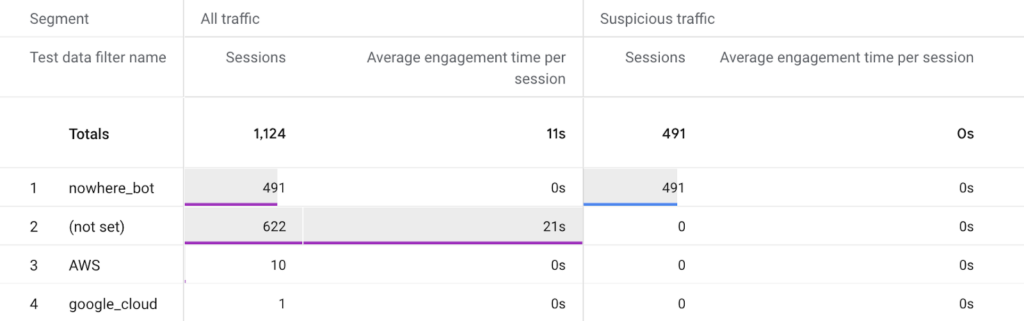
I went back to my GA4 Exploration to see how well screen resolution correlates to the suspicious traffic and discovered something else. Browser version is not available as a dimension in the GA4 Tech Details report, but it is available as a dimension in Explorations. I added it to my Exploration as well and the correlation was perfect! 100% of the suspicious traffic had an 800×600 screen resolution and Chrome 19.0.0.0. Conversely, no non-suspicious traffic did. This was excellent news, because both browser version and screen resolution are easy to get in Google Tag Manager, which meant I had a way of definitively filtering the traffic!
Adding a traffic filter in Google Tag Manager
My next task was to populate the GA4 traffic_type parameter with a value I could exclude with a GA4 traffic filter. At this point it was smooth sailing. I created a custom JavaScript variable in GTM that returns the value ‘nowhere_bot’ if the screen resolution is 800×600 and the browser version is 119.0.0.0.
I then added a traffic_type parameter to the GA4 Google Tag: